The Open File operator has been introduced in the 5.2 version of RapidMiner. It returns a file object for reading content either from a local file, from an URL or from a repository blob entry. Many data import operators including Read CSV, Read Excel and Read XML has been extended to accept a file object as input. With this new feature, now you can process live data feeds directly in RapidMiner.
Many data import operators provide a wizard to guide users through the process of parameter setting. Unfortunately, wizards can not use file objects, they always present a file chooser dialog on start. When dealing with data from the web, you can make use of the wizards according to the following scenario: download the data file and pass your local copy to the wizard. After successful import you can even delete the local file. Data import operators ignore their file name parameter when they receive a file object as input.
In the following a simple use case is presented for demonstration purposes.
The United States Geological Survey’s (USGS) Earthquake Hazards Program provides real-time earthquake data. Real-time feeds are available here. Data is updated periodically and is available for download in multiple formats. For example, click here to get data in CSV format about all M2.5+ earthquakes of the past 30 days (the feed is updated every fifteen minutes).
Let’s see how to read this feed in a RapidMiner process. First, download the feed to your computer. The local copy is required only to set the parameters of the Read CSV operator by using the Import Configuration Wizard. For this purpose you can use a smaller data file, for example this one.
Import the local copy of the feed using the wizard. Select the following data types for the attributes:
- Src (source network): polynomial
- EqId: polynomial
- Version: integer
- Datetime: date_time
- Lat: real
- Lon: real
- Magintude: real
- NST (number of reporting stations): integer
- Region: text
Important: the value of the date format parameter must be set to E, MMM d, yyyy H:mm:ss z to ensure correct handling of the Datetime attribute. For details about date and time pattern strings consult the API documentation of the SimpleDateFormat class (see section titled Date and Time Patterns). It is also important to set the value of the locale parameter to one of the English locales.
Once the local file is imported successfully, drag the Open file operator into the process and connect its output port the input port of the Read CSV operator. Set the parameters of the Open file operator according to the following: set the value of the resource type parameter to URL, and provide the URL of the feed with the parameter url.

A RapidMiner process that uses the Open file operator to read a data feed from the web
Now you can delete the local data file, the operator will read the feed from the URL when the process is run.
You can download the complete RapidMiner process here.
")
 denotes the support count of the itemset
denotes the support count of the itemset  and the function
and the function  -itemsets from the set of frequent
-itemsets from the set of frequent 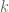 -itemsets.
-itemsets. on line 2 of Algorithm 6.2 is defined as the set of consequents of rules derived from
on line 2 of Algorithm 6.2 is defined as the set of consequents of rules derived from  with one item in the consequent. However, this implicitly assumes that rules with 1-item consequents are already available. [2] also states that a separate algorithm is required to generate these rules (see page 14):
with one item in the consequent. However, this implicitly assumes that rules with 1-item consequents are already available. [2] also states that a separate algorithm is required to generate these rules (see page 14): .
.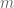 is not the cardinality of set
is not the cardinality of set  .) I think that the first two lines of Algorithm 6.3 are unnecessary and can be omitted.
.) I think that the first two lines of Algorithm 6.3 are unnecessary and can be omitted.")


 subsets as the training set and its performance is evaluated on the current subset. This means that each subset is used for testing exactly once. The result of the cross-validation is the average of the performances obtained from the
subsets as the training set and its performance is evaluated on the current subset. This means that each subset is used for testing exactly once. The result of the cross-validation is the average of the performances obtained from the 







